
Deep Dive on ML.GENERATE_TEXT()
Key information about running Gemini 1.5 Flash and Pro Reliably

Previously, I published a video showcasing an architecture that leverages Continuous Queries and LLMs to categorise customer feedback.
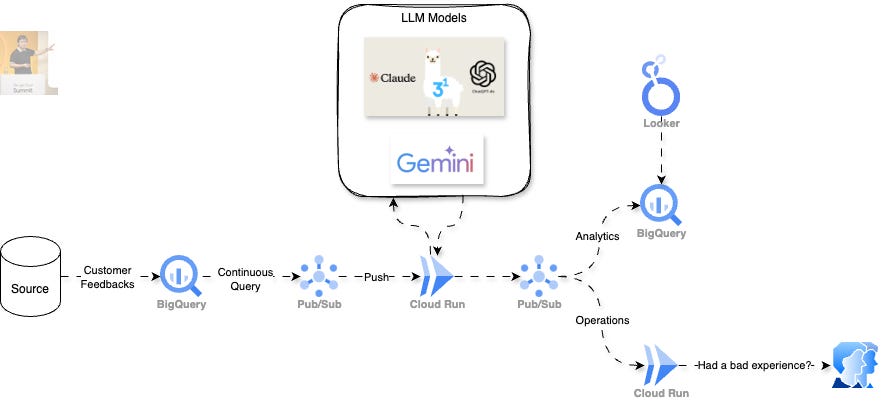
In the design, I mentioned being hesitant to use the ML.GENERATE_TEXT() BigQuery function. While it could be an ideal solution for scenarios involving less technical users or those who primarily use SQL as their daily programming language, there were concerns about reliability. If resolved, this function would be a highly appealing option.
Since then, I’ve had insightful discussions with the Google Cloud engineering team working on integrating ML functions and Gemini APIs. I’m happy to share that several issues have been clarified and addressed, making it a much more compelling solution.
The Cloud Run-based alternative remains valid, offering more flexibility and access to various LLM models and customisation. However, here's what I’ve learned to save you the trouble of finding these insights yourself.
Gemini 1.5 Flash
The Gemini 1.5 Flash model is typically the default go-to for simple tasks like semantic analysis and categorisation. It also has a higher default quota of 200 QPM (Requests Per Minute).
However, I noticed my project showed a quota of only 5 QPM, which is unusual. If you encounter similar issues, ensure your quota is raised; otherwise, your workload will constantly hit limits.

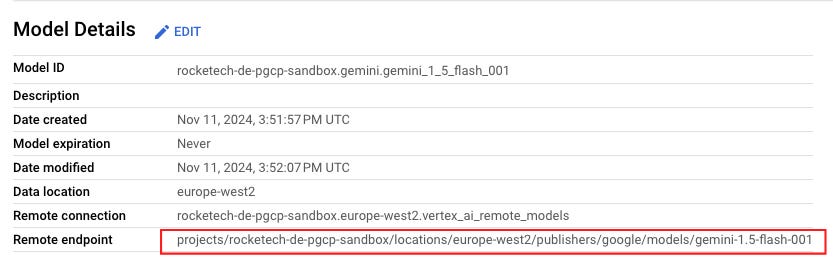
To use this, set your model to flash-001, which has been the most reliable in my testing. Based on a rough analysis, processing 1 million user feedback records (averaging 39 tokens each) will cost under $4.
Gemini 1.5 Pro
The Gemini 1.5 Pro model offers improved reasoning and generates better results with less prompt engineering. However, it comes with:
A lower
60 QPMdefault quota, andA significant cost increase, estimated at $60 for 1 million records.
Gemini 1.0
Avoid using this model as it’s being phased out and lacks the quality of the 1.5 models.
What’s been resolved
Previously, I highlighted key concerns, including the ML function hanging without explanation, even for small datasets like five records, despite quotas not being exceeded.
The Google Cloud team identified that this was likely caused by misaligned quotas between BQML and Vertex AI, leading to exponential retries. A fix has been implemented (thank you!), aligning the quotas on both sides. I tested both Gemini 1.5 Flash and Pro models and have not observed any hanging behaviours since.
To further test, I deliberately exceeded the quota (e.g., sending 200 records with a 100 QPM quota). The process completed in about 2 minutes, doubling the time but without hanging—a predictable and improved outcome.
Another key point I initially questioned about the hanging behaviour was why the query didn’t fail when hitting the quota or whether it should terminate in such cases. Upon further reflection, I believe it’s crucial that the query does not fail, especially for Continuous Queries, which operate 24/7 like a Dataflow streaming job. Failing due to exceeded quotas could lead to production incidents. Instead, it’s better to set up monitoring and alerts to track quotas and scale them as needed based on workload requirements.
Other issues observed
With the Gemini 1.5 Flash model, around 20% of responses return null, which can be problematic. Discussions with the Google Cloud engineering team revealed this could be linked to Responsible AI (RAI) filtering.
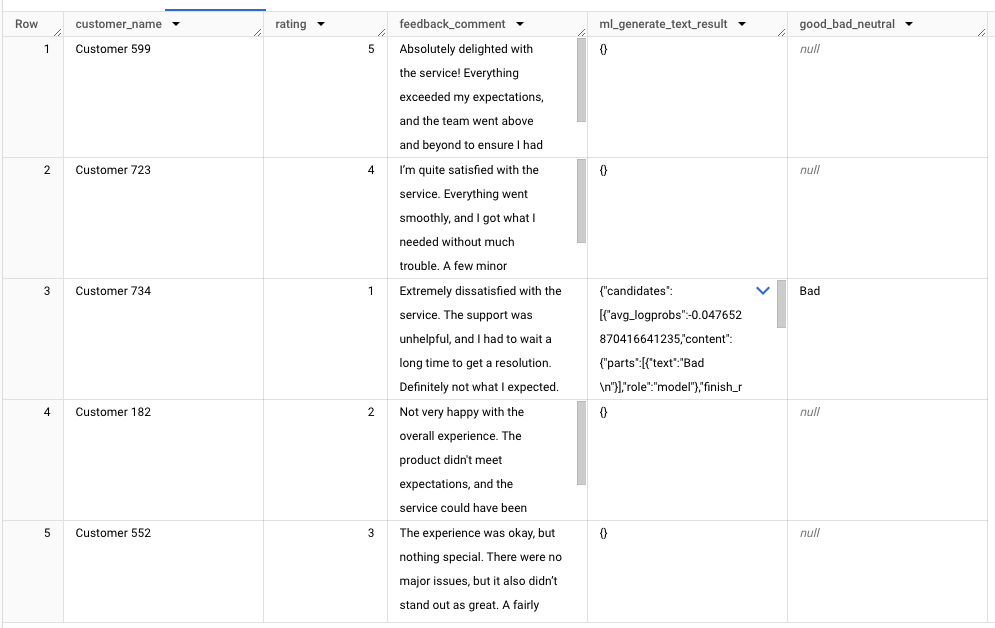
The current workaround is to adjust the SAFETY_SETTINGS, though I’ve only encountered this issue with the 1.5 Flash model, not the 1.5 Pro. However, this adjustment doesn’t seem to fully resolve the null output issue with the following settings. That said, once the bug is fixed, it should provide clarity on why no output was generated.
STRUCT(ARRAY<STRUCT<category STRING, threshold STRING>>[
STRUCT('HARM_CATEGORY_HATE_SPEECH' AS category, 'BLOCK_ONLY_HIGH' AS threshold),
STRUCT('HARM_CATEGORY_DANGEROUS_CONTENT' AS category, 'BLOCK_ONLY_HIGH' AS threshold),
STRUCT('HARM_CATEGORY_HARASSMENT' AS category, 'BLOCK_ONLY_HIGH' AS threshold)
] as safety_settings)002 models and Dynamic Shared Quota
The recently released Gemini 1.5 Flash and Pro 002 models introduced a new Dynamic Shared Quota (DSQ) system.

While promising, my experience with these models shows:
They are still less reliable than the 001 models, with exponential retry issues resurfacing.
Quota usability isn’t currently reflected in the All Quotas page.
I recommend waiting for further improvements before fully adopting the 002 models.
Quotas
To avoid bottlenecks, ensure you’re monitoring and raising the correct quotas. The key quota to track is:
Generate content requests per minute per project per base model per minute per region per base_modelThis quota has two dimensions:
Region: e.g., europe-west2.
Base Model: e.g., gemini-1.5-flash, gemini-1.5-pro.
Raise these quotas appropriately to match your workload demands.
Summary
Recent improvements in BigQuery's ML.GENERATE_TEXT() function and Gemini APIs have resolved major issues like query hanging and quota misalignment, making it a more stable solution. While Gemini 1.5 Flash is cost-effective, 1.5 Pro offers higher-quality outputs at a premium.
Continuous Queries would benefit from predictable behaviour when quotas are exceeded, but monitoring and scaling remain key points to consider. The newer 002 models show potential but need further refinement before full adoption.
Need to modernise your data stack? I specialise in Google Cloud solutions, including migrating your analytics workloads into BigQuery, optimising performance, and tailoring solutions to fit your business needs. With deep expertise in the Google Cloud ecosystem, I’ll help you unlock the full potential of your data. Curious about my work? Check out My Work to see the impact I’ve made. Let’s chat! Book a call at Calendly or email richardhe@fundamenta.co. 🚀📊