


Sharing Sensitive Data Using Data Clean Room on BigQuery
Use Data Clean Room as an alternative to policy tags and data masking

Problem Statement
Policy Tags on BigQuery allow you to tag sensitive data at the column level and enforce these tags by requiring an additional IAM role to access sensitive data. This feature is effective for securing sensitive information by restricting access to most teams. Furthermore, the Masked Reader IAM role provides a way to grant access to masked data (details here), mitigating some data access risks while still offering users partial, less sensitive data.
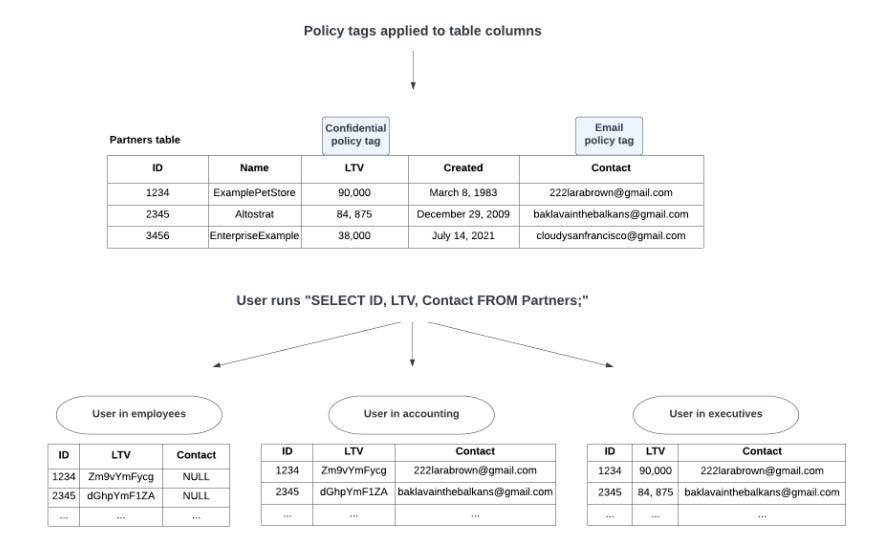
However, several challenges arise:
Enforcing Policy Tags Is Challenging
Not every organisation begins with a greenfield project, and even when they do, tagging all data accurately is difficult. Tags often evolve over time, and enforcing these changes can have significant downstream impacts. Users may lose access to data they previously relied on, leading to disruptions in business continuity, incidents, and complaints.
Diminished Data Usefulness
While masking reduces data sensitivity, it can also lead to reduced granularity, which diminishes the usefulness of the data. For example, fields like address details, postcodes, coordinates, IP addresses, demographics, age, and gender lose much of their value post-masking.
Privacy Risks Are Not Always Mitigated
Tagging all sensitive data is challenging, let alone enforcing the tags effectively. Even with these measures, privacy risks remain. For instance, users, particularly in BI and reporting contexts, can still access row-level data. If individual columns are unmasked or insufficiently masked, this can lead to the re-identification of individuals through row-level information.
Addressing these challenges requires substantial effort in data modelling, sharing, and management, alongside ongoing negotiations about permissible data access across the organisation.
Data Clean Room as an Alternative
Data Clean Room, a feature of Analytics Hub, offers a compelling solution for mitigating many data access risks.
Although often discussed in the context of secure data sharing between organisations or with third parties, Data Clean Room can also help minimise re-identification risks. It enables querying granular data across all columns, including sensitive ones, without exposing individual-level information.
While this approach doesn’t solve all problems, it addresses a significant portion of privacy risks within organisations, especially in analytics, BI, and reporting contexts. In these scenarios, analysts typically require access to granular data but rarely need row-level details.
Data Clean Room ensures that queries cannot return single-row data, or exclude aggregations that involve fewer rows than a specified threshold. For example, analysts can convert dates of birth into age groups using aggregation but cannot run queries like SELECT date_of_birth LIMIT 10; as this would reveal individual records.

Key Building Blocks of Data Clean Room
Below are the key concepts for effectively utilising Data Clean Room, along with examples of common analytics use cases to demonstrate its minimal impact on outcomes.
Dummy Data Setup
To illustrate, let’s consider three dummy tables: customers, products, orders and order_items. These are typical e-commerce datasets used for analytics and reporting.
Customers: Contains sensitive PII fields.
Products: Contains product-related information.
Orders: Contains transaction-level data.
Order Items: Contains item level data for each transaction.
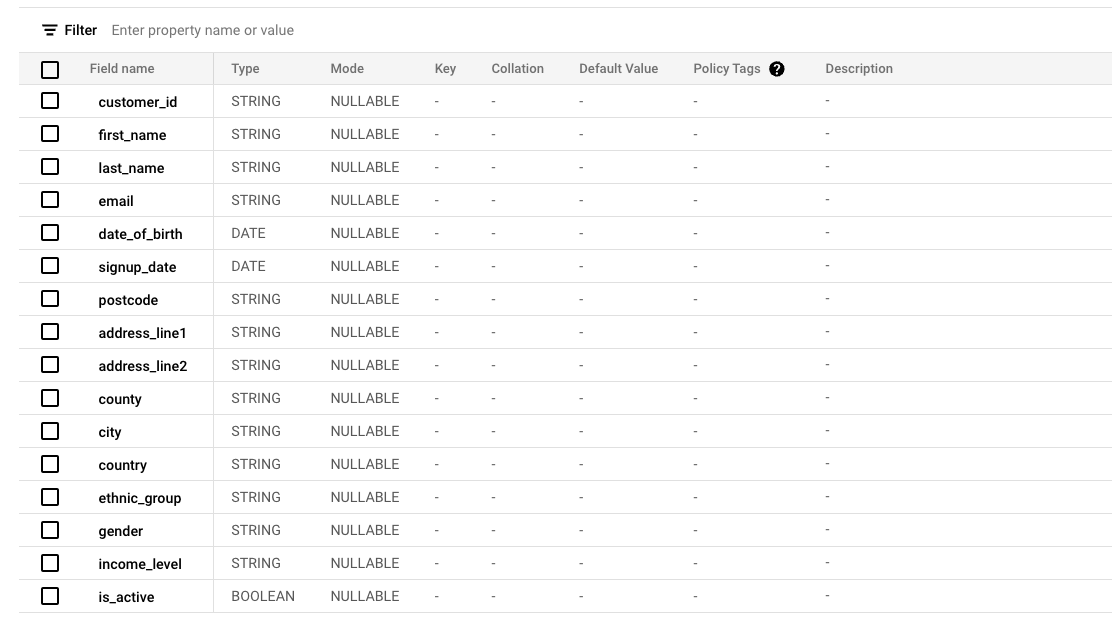
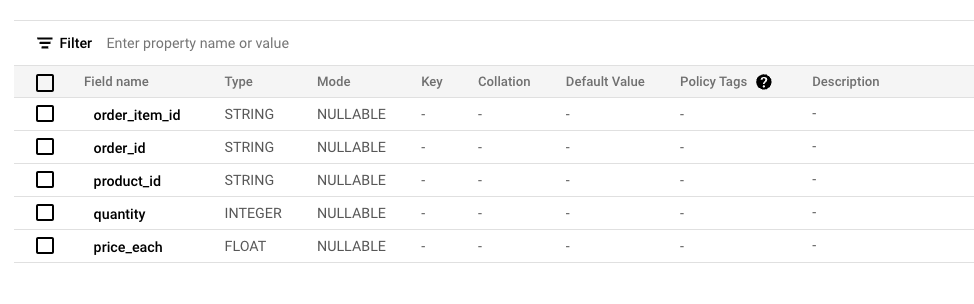
The goal is to protect sensitive information in the customers table while retaining its usefulness for analysts. This is achieved by creating a view, which is required by Data Clean Room.
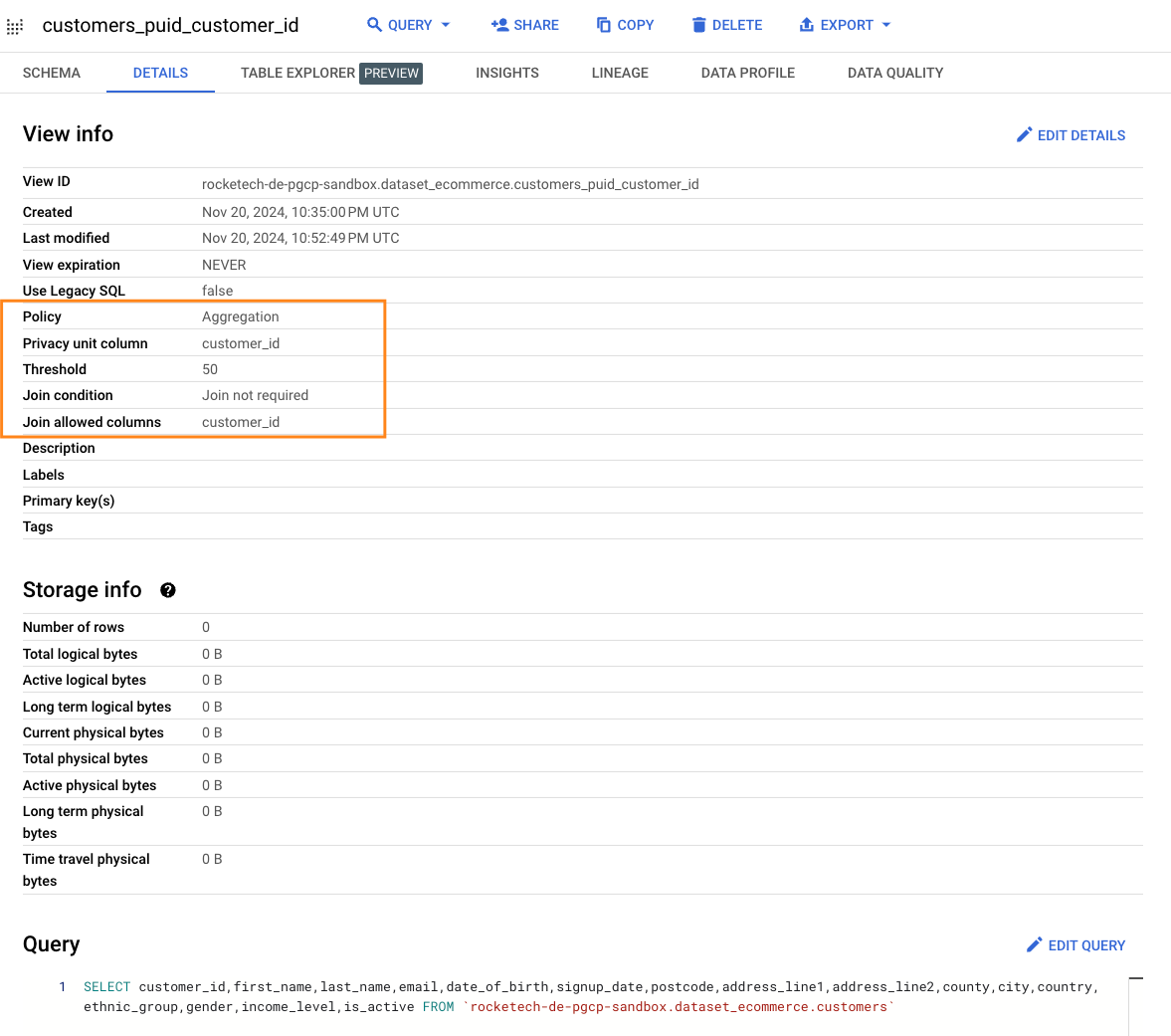
Five Key Components of the View
Policy:
The Aggregation policy ensures data cannot be queried without aggregation functions. Just in case you are wondering… Functions likeminandmaxat the row level are prohibited.Privacy Unit Column:
This column acts as the unique key (e.g.,customer_id) that controls what never gets exposed at the row level subject to this key. It also governs thresholds and other privacy configurations.Threshold:
Defines the minimum number of rows that must be aggregated in queries against the Privacy Unit Column. For example, if an age group contains fewer than 10 individuals, setting the threshold to 10 ensures this group is excluded, safeguarding privacy.Join Condition:
Specifies whether joins are required. This is more relevant for inter-organisational data sharing than within the same organisation.Join Allowed Columns:
Restricts join operations to specific columns (e.g.,customer_id). Joins using any other columns are disallowed.
Example Queries
Let’s look at a few examples
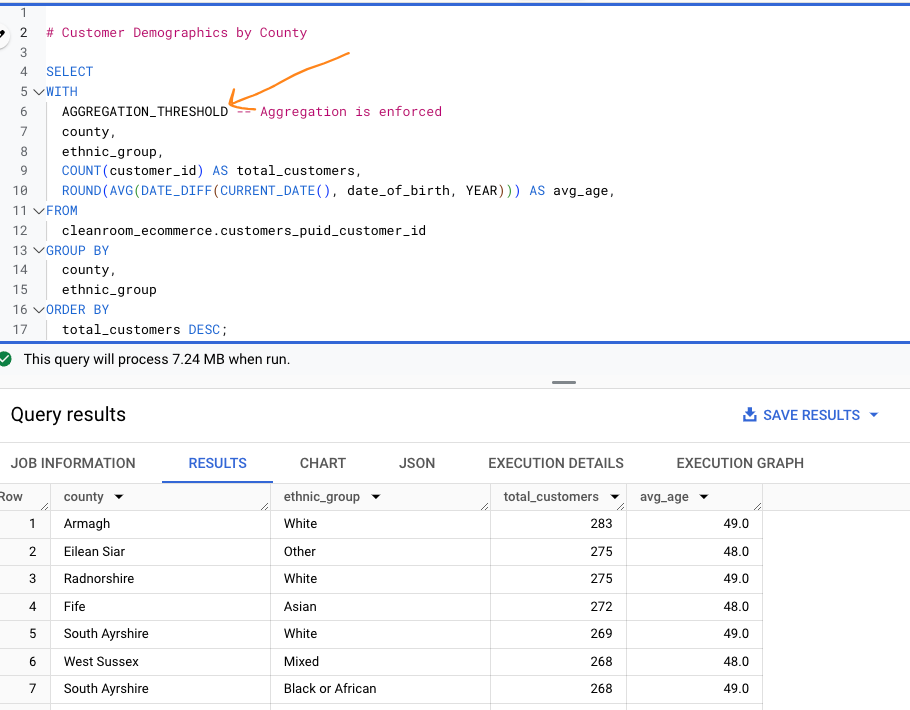
Customer Demographics by County - This query groups customer demographics by county. Aggregation is enforced using the
AGGREGATION_THRESHOLD.
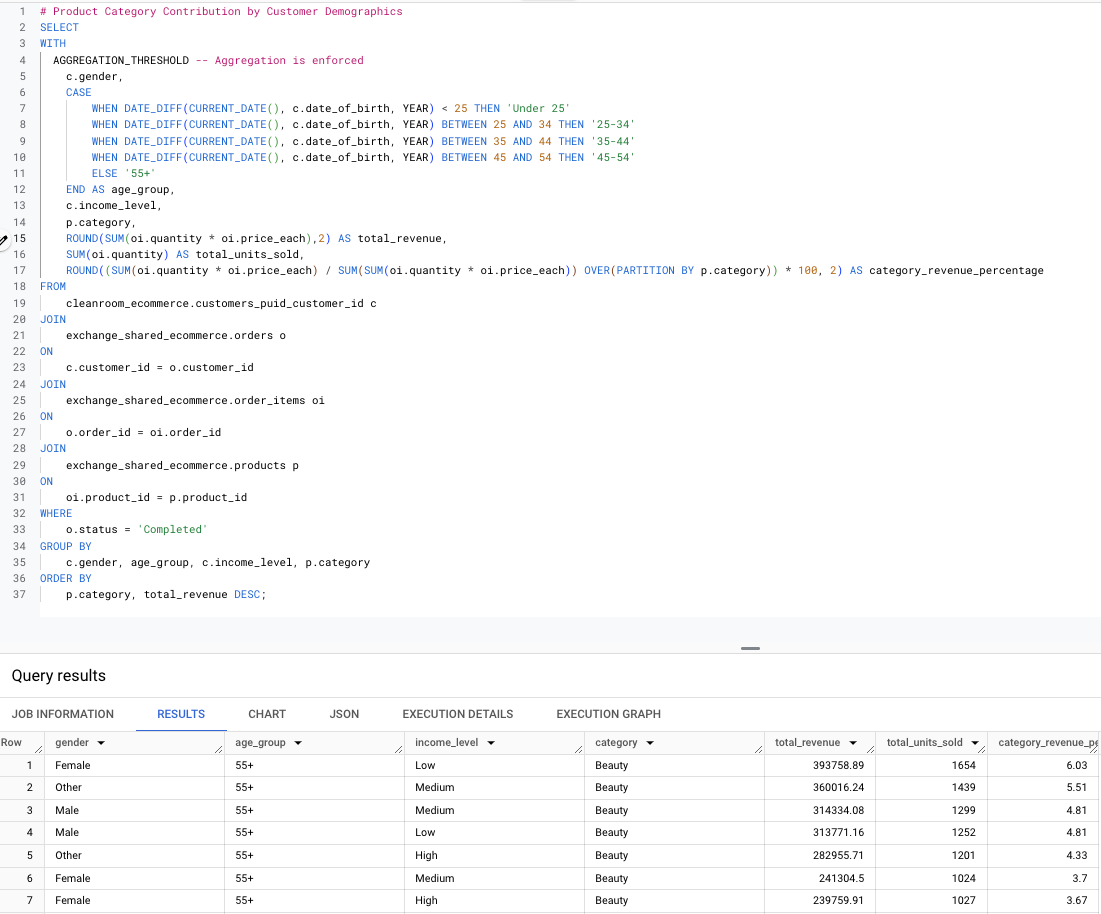
Product Category Contribution by Customer Demographics - This query combines data from multiple tables, including the customer view, to analyse product category contributions by customer demographics.
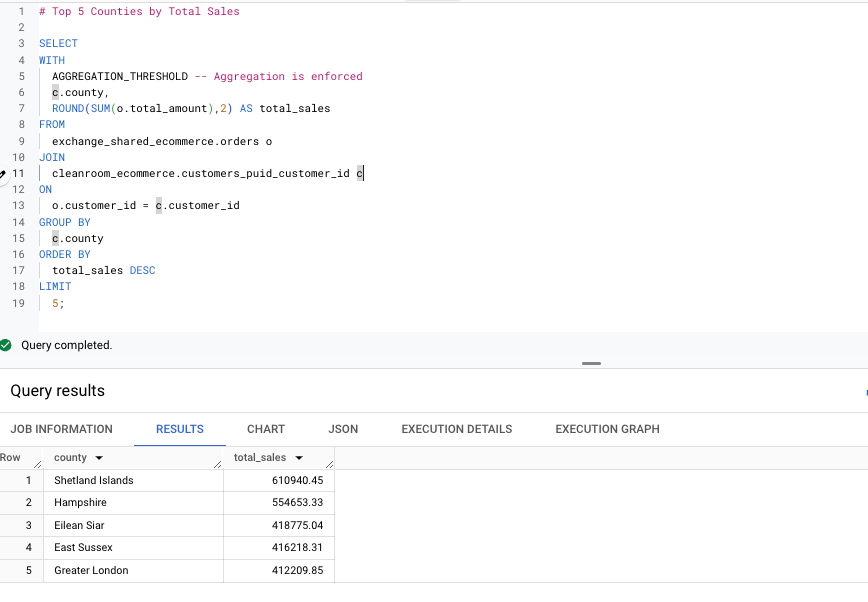
Top 5 Counties by Total Sales - This query identifies the top five counties by total sales.
You can see none of these queries are impacted by the privacy customer view.
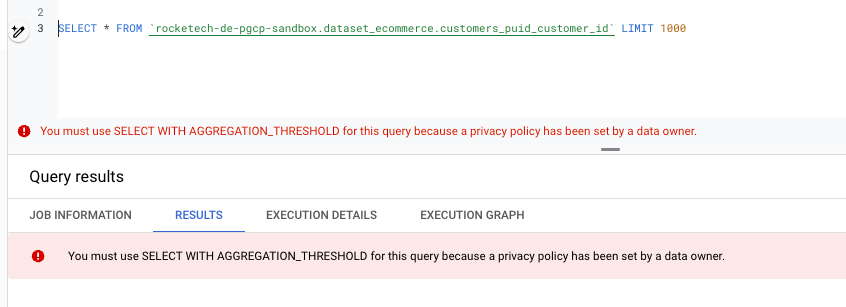
However, attempting to query individual row-level data results in a privacy error, effectively preventing unauthorised access.
Summary
In my view, Data Clean Room is not only a valuable tool for secure data sharing with third parties but also a highly effective solution for internal use cases, such as analytics, BI, and reporting, to reduce privacy risks.
However, it is not a universal solution. Teams requiring row-level data—such as those building core data models, machine learning models—may still need traditional approaches like policy tags or data sensitivity reduction during modelling.
Lastly, collaboration with the privacy team is essential to ensure appropriate thresholds and privacy configurations. Misconfigurations can lead to either inaccurate data or increased re-identification risks.
The code such as SQL scripts and examples for generating the dummy data and tables are available on GitHub.
Need to modernise your data stack? I specialise in Google Cloud solutions, including migrating your analytics workloads into BigQuery, optimising performance, and tailoring solutions to fit your business needs. With deep expertise in the Google Cloud ecosystem, I’ll help you unlock the full potential of your data. Curious about my work? Check out My Work to see the impact I’ve made. Let’s chat! Book a call at Calendly or email richardhe@fundamenta.co. 🚀📊